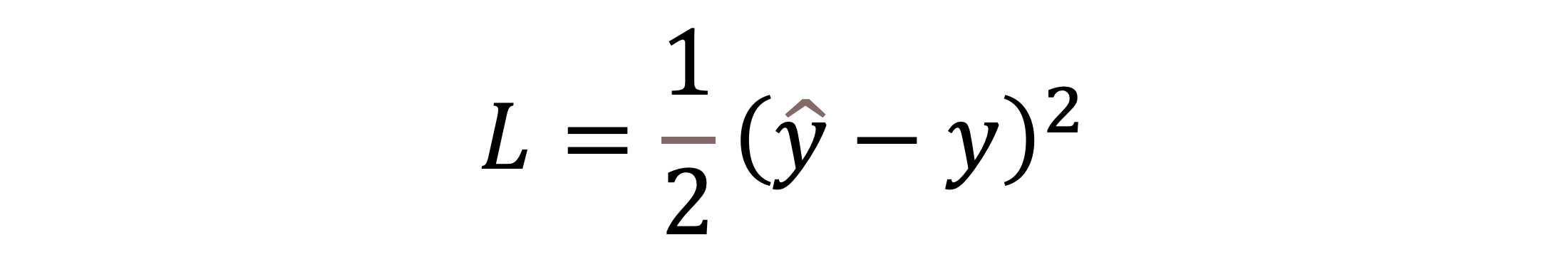
Deep-dive: Neuron
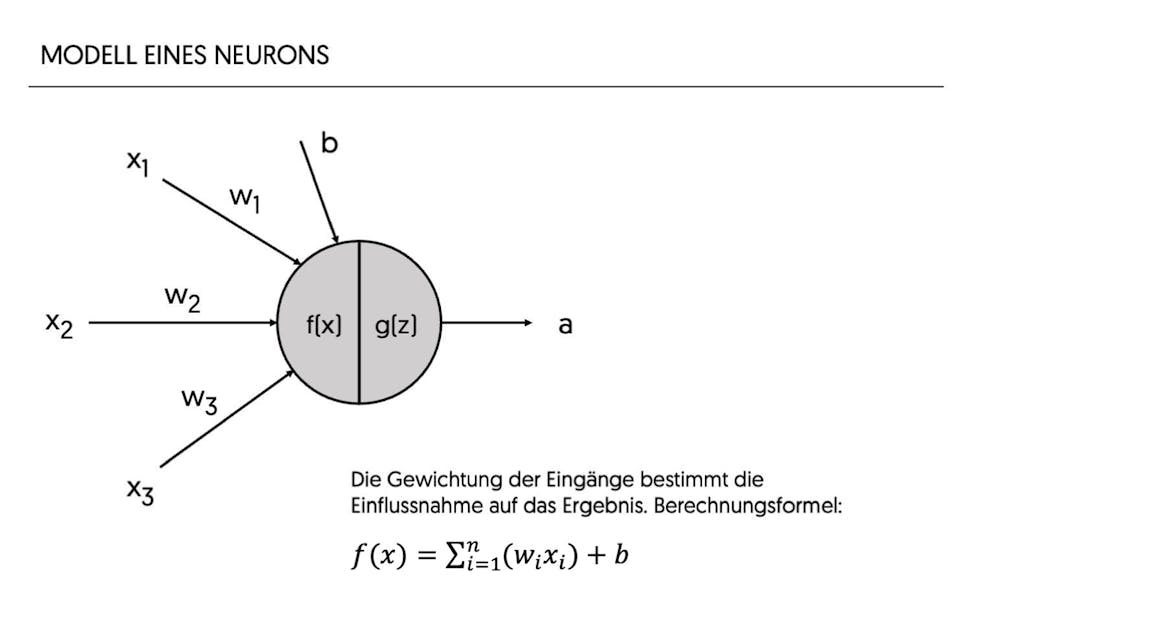
Betrachten wir zum besseren Verständnis ein einzelnes Neuron im Detail. Das Neuron ist die grundlegende Einheit eines jeden neuronalen Netzes. Im Folgenden werden Eingaben, Gewichtungen, Bias und Aktivierungsfunktionen beschrieben.
Deep-dive: Neuron
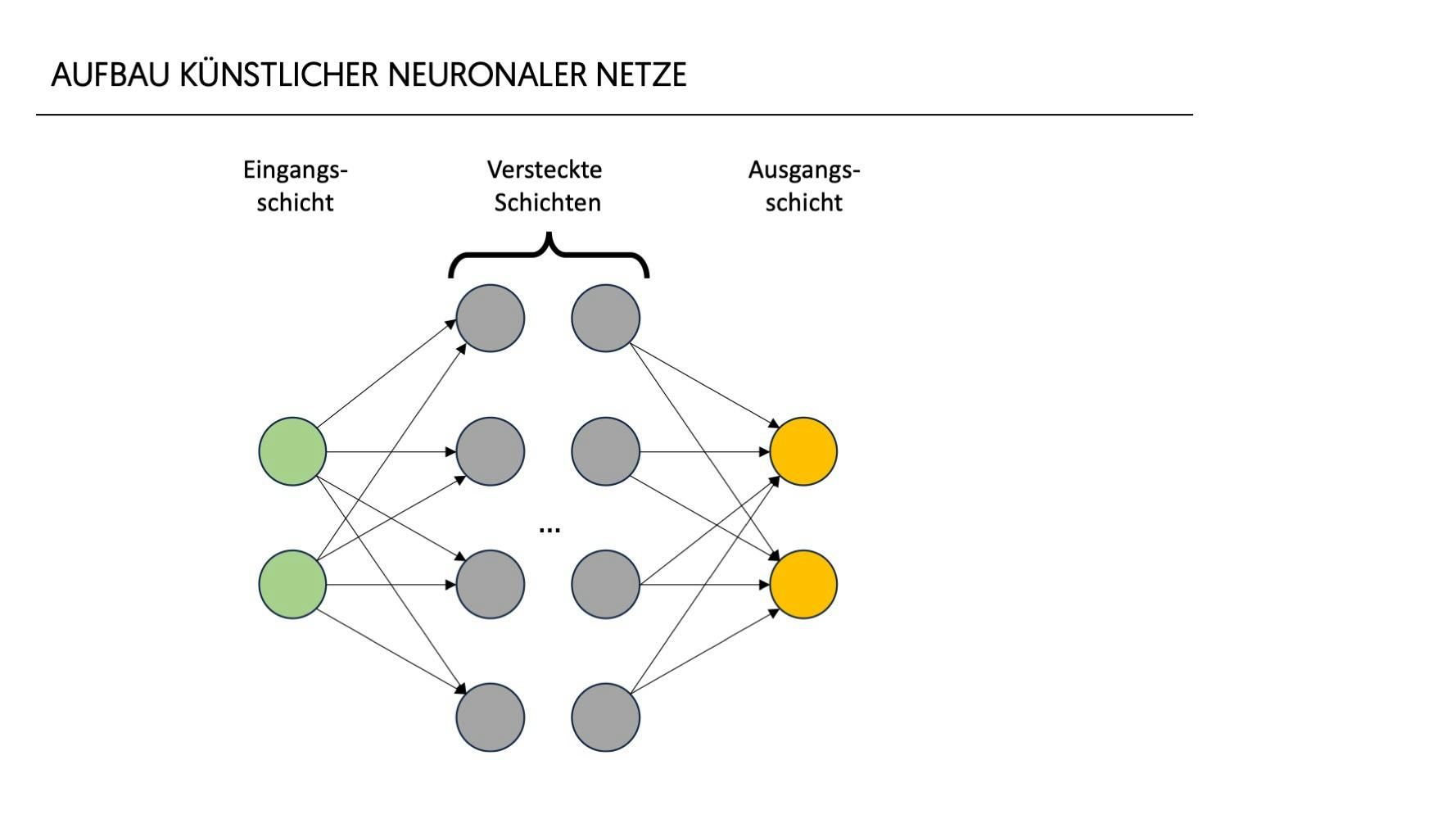
Das Neuron ist die grundlegende Einheit eines jeden künstlichen neuronalen Netzes. Es empfängt Eingaben x1 – xn, verarbeitet sie und gibt ein Ergebnis a aus. Jede Eingabe x eines Neurons wird mit einer entsprechenden Gewichtung w multipliziert. Diese gewichteten Eingaben werden summiert. Ein zusätzlicher Wert, der sogenannte Bias b, wird hinzugefügt, um das Modell flexibler und anpassungsfähiger zu machen und die Verschiebung der Aktivierungsfunktion zu steuern. Die Gewichtungen der Eingänge modellieren, wie stark die jeweiligen Eingänge das Ergebnis eines Neurons beeinflussen, wohingegen der Bias modelliert, wie wichtig das Neuron für das Ergebnis des Netzes ist. Die Berechnung erfolgt entsprechend nebenstehender Formel.
Die resultierende Summe z wird dann durch eine Aktivierungsfunktion g(z) geleitet, um den Ausgang des Neurons zu erhalten: a = g(f(x))
Die Wahl der Aktivierungsfunktion g kann die Performance des Netzes stark beeinflussen und hängt oft von der Art des zu lösenden Problems ab. Zwei gängige Aktivierungsfunktionen sind:
- Die Sigmoid-Funktion gibt Werte zwischen 0 und 1 aus und wird oft in binären Klassifikationsproblemen verwendet. Die Sigmoid-Funktion könnte beispielsweise in der Ausgabeschicht eines neuronalen Netzes eingesetzt werden, um zu entscheiden, ob eine E-Mail Spam (1) oder nicht (0) ist, basierend auf verschiedenen Merkmalen der E-Mail.
- Die ReLU (Rectified Linear Unit) Aktivierungsfunktion setzt alle negativen Werte auf Null und lässt positive Werte unverändert. Sie wird oft in tieferen Netzen bevorzugt, da sie das Training beschleunigen kann. Sie findet beispielsweise in Netzen zur Bildklassifikation Anwendung, um komplexe, hierarchische Muster in Bildern zu erkennen und zu lernen, welche zur Identifikation von Objekten in Bildern beitragen.
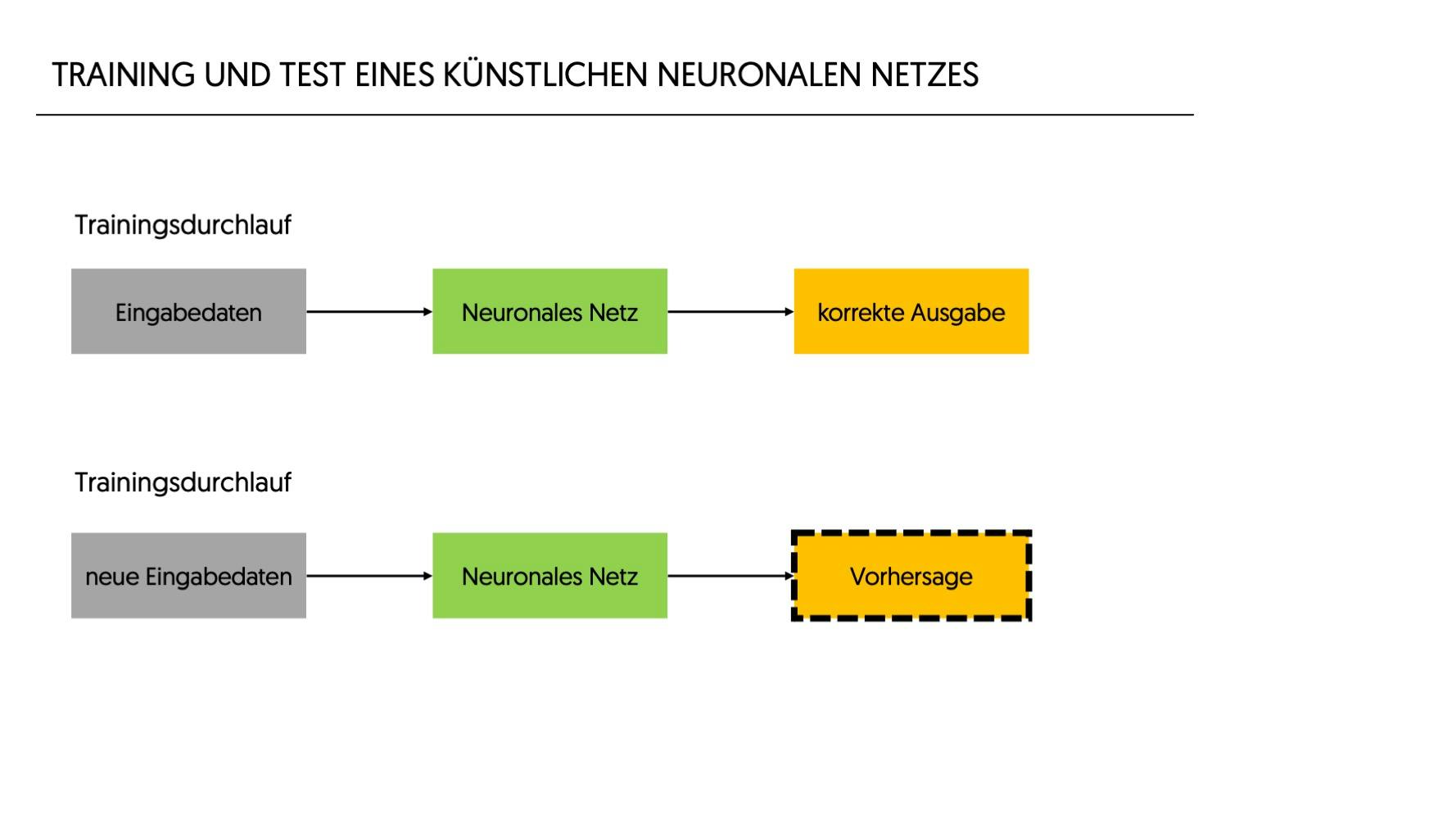
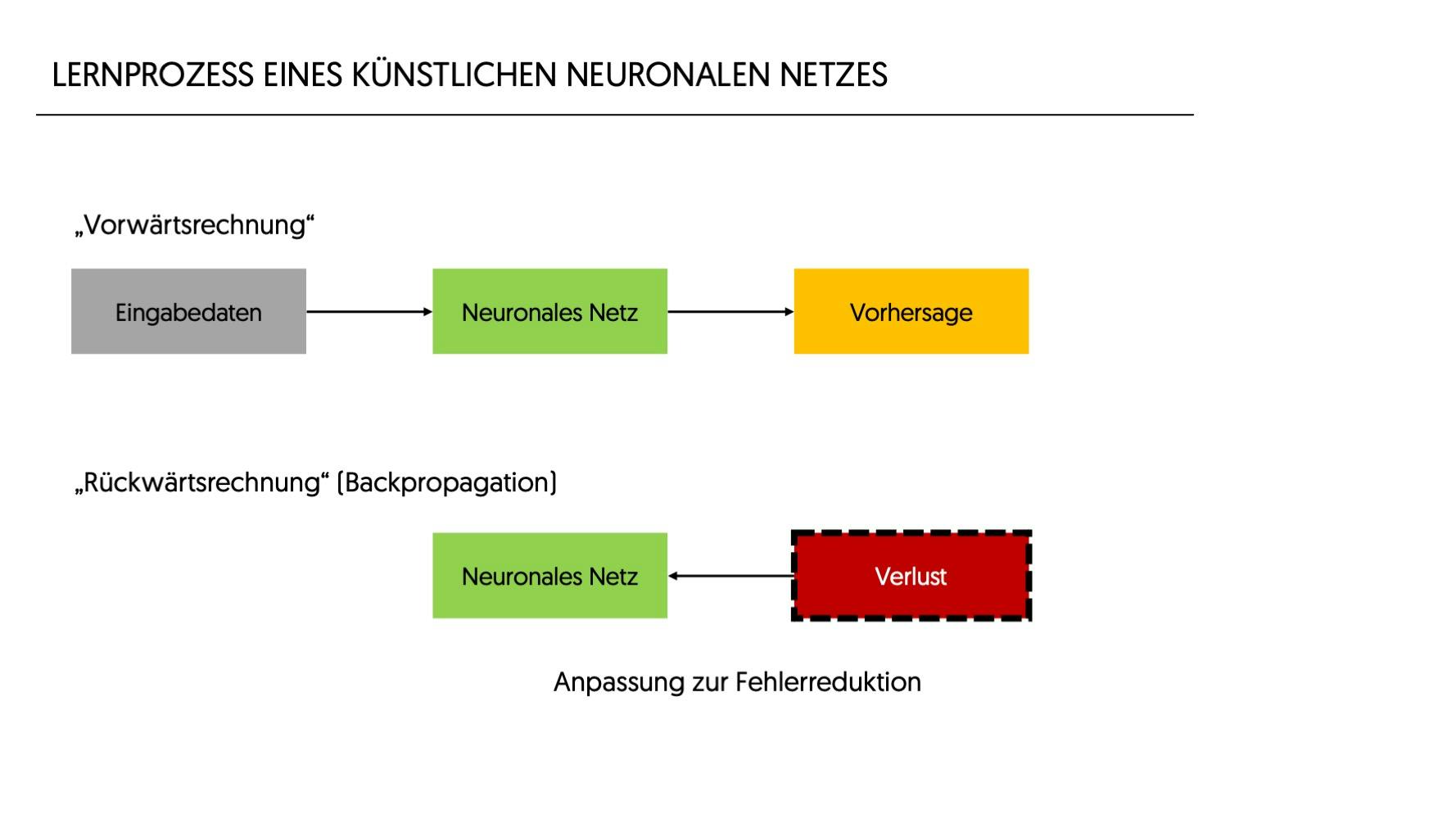
Die Ausgabe eines Neurons dient dann wiederum als Input für die nächsten Neuronen.