
Mit der Digitalisierung wird oft der Vergleich zur industriellen Revolution gezogen. Im Vergleich zur technologiegetriebenen Produktion liegt der Gedanke nahe, dass auch die IT und Investments in neue Technologien, die Produktivität erhöhen. Allerdings ist das bei neuen IT-Technologien nicht immer offensichtlich. Als Produktivitätsparadoxon wird eine Hypothese bezeichnet, die der Nobelpreisträger Robert Solow formulierte: „Computer finden sich überall – außer in den Produktivitätsstatistiken“.
Dafür gibt es mehrere Gründe und Erklärungen: So werden häufig Managementfehler genannt, die dazu führen, dass Potenziale beim Einsatz neuer Technologien zu wenig genutzt werden. Außerdem ist der Umgang mit dem erhöhten Informationszuwachs herausfordernd.
Das Paradoxon gilt auch für Investments in Big Data und Advanced Analytics Themen. Durch den Digitalisierungstrend wurden hohe Investitionen in die Disziplinen und dazugehörigen Technologien getätigt. Während einige Unternehmen direkte Produkt- oder Produktivitätsvorteile daraus gezogen haben, suchen andere noch nach dem positiven Effekt.
Data Thinking ist relevant für alle Organisationen, die datengetrieben Produkte entwickeln, Probleme lösen, Prozesse optimieren, oder planen, damit anzufangen. In diesem Artikel erläutern wir, warum Data Thinking notwendig ist und wie Vorteile entstehen.
In der Fertigung werden über Predictive Maintenance mittels historischer und aktueller Messwerte der zukünftige Zustand von Maschinen ermittelt. Instandhaltungsmaßnahmen werden so zum Zeitpunkt des tatsächlichen Bedarfs durchgeführt. Über Mustererkennung können sämtliche Anomalien identifiziert werden und Probleme werden erkannt, bevor sie auftreten. Prozesse können mit der Unterstützung von künstlicher Intelligenz auf Wirtschaftlichkeit und Qualität geprüft und optimiert werden. Es gibt eine Reihe etablierter Einsatzszenarien, die mittels Advanced Analytics die Vorgänge in Unternehmen merklich optimieren. Ein Return on Invest für die notwendige Technologie und das Wissen kann schnell erreicht werden, wenn die passenden, gewinnbringenden Anwendungsfälle für Advanced Analytics im Unternehmen richtig identifiziert und damit verbundene Annahmen validiert werden.
Eine Forbes-Studie verdeutlicht, dass die Bedeutung von Daten zur Innovation erkannt wird, aber die Voraussetzung einer Datenkultur in vielen Unternehmen fehlt.
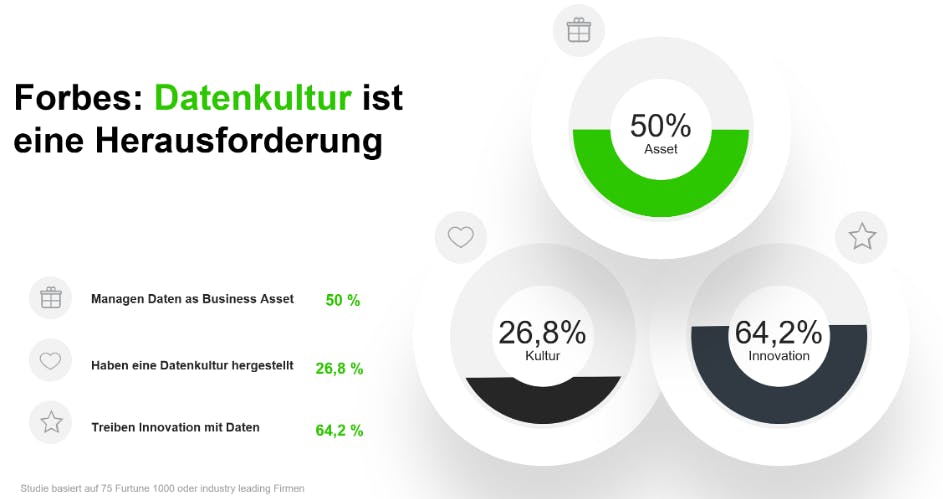
Eine erfolgreiche Datenkultur zeichnet aus, dass Daten von allen relevanten Organisationseinheiten verstanden werden. Mit diesem Grundverständnis werden Daten aktiv zur Problemlösung beispielsweise in Optimierungsinitiativen, Produktentwicklung, oder im Reporting eingesetzt. Der fachliche Umgang mit Daten wird nicht der IT zugeteilt, sondern prinzipiell im Fachbereich verankert.
Die größten Pain-Points von Unternehmen mit Daten sind in folgender Liste zusammengefasst:
Data Thinking soll die genannten Pain Points adressieren und über erfolgreiche, funktionierende Prototypen die Datenkultur im Unternehmen fördern. Data Thinking ist eine Methode, um die zahlreichen Techniken und Technologien der Data Science für alle Personen, die nicht zu den Datenspezialisten gehören, greifbar zu machen, um solche Anwendungsfälle zu identifizieren, die wirklich Gewinn und Mehrwerte für das Unternehmen bringen.
Dabei werden bewährte Methoden des Design Thinkings mit denen der Data Science kombiniert. Design Thinking wird zur Identifikation von echten Bedarfen und schnellen, günstigen Entwicklung von Prototypen und MVPs genutzt, während die Data Science dafür sorgt, dass Prototypen funktionieren und Erfolge messbar werden.
Data Thinking kombiniert bewährte Kernelemente aus Design Thinking und Data Science zu einer neuen Methodik.

Schritt für Schritt werden einzelne Use-Cases im Unternehmen gefunden und es wächst über die Erfolge eine Datenkultur heran.

Mittels der Methodikkomponenten aus Design Thinking werden fachliche Use-Cases kreativ erarbeitet. Von Anfang an stehen dabei ausschließlich Use-Cases im Fokus, die mittels Daten verbessert, oder sogar ermöglicht werden können. Der wichtigste Faktor ist der geschäftliche Impact, der durch den Use-Case erzeugt wird. Mittels Analysen der Kundenbedarfe über Pains & Gains in einem Value Case Canvas werden Use-Cases identifiziert und validiert, die echte Bedarfe decken. Dann wird echtes Feedback von Nutzern oder Kunden eingeholt. Es sollen dabei früh Anwendungsfälle eliminiert werden, die nur vermeintlich eine Relevanz haben und somit näher am echten Nutzer oder Kunden gearbeitet werden.
Eine wichtige Fragestellung des Data Thinkings ist, an welcher Stelle man im Unternehmen gern „die Spreu vom Weizen trennen“ möchte, oder wo man in „die Zukunft schauen“ will. Denn bei diesen Fragestellungen ist Advanced Analytics besonders hilfreich, vorausgesetzt, die dafür relevanten Daten können identifiziert werden.
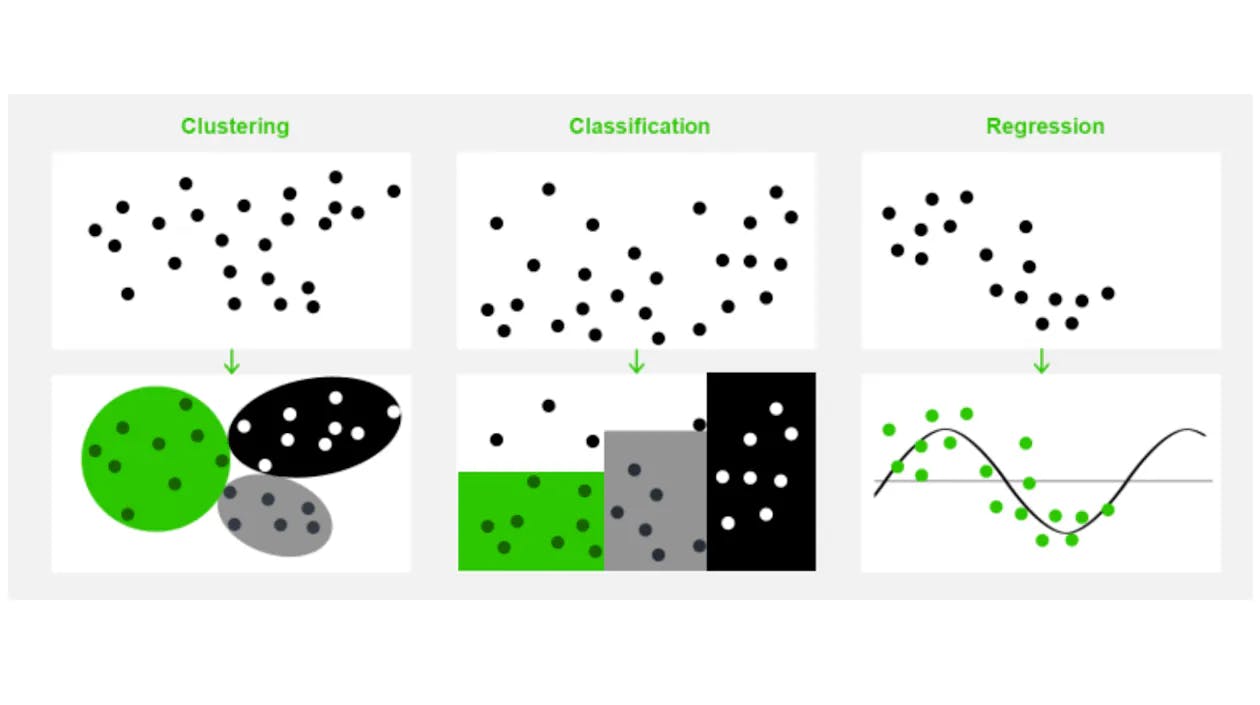
Die Methoden und Technologien der Data Science sind komplex. Data Science vermittelt die grundlegenden Denkweisen und stellt eine Überleitung zu den Spezialisten her.
Sind die ersten Phasen des Design Thinkings durchgeführt worden, gelangt man in die Ideation-Phase. Dort wird das Kernelement des Data Thinkings bearbeitet: Das Data Thinking Canvas.
Das Data Thinking Canvas orientiert sich stark am Use-Case Canvas, beinhaltet aber auch zentrale Anforderungen der Data Science, die für weitere Schritte notwendig sind. Beim Konzipieren der Use-Cases wird permanent überlegt, an welchen Stellen bereits Primärdaten vorhanden sind, welche Sekundärdaten abgeleitet werden können und welche Daten möglicherweise im Hintergrund generiert werden, die dem Unternehmen noch nicht bekannt sind. Beispielsweise haben viele Unternehmen Mitarbeiter im Außendienst, die mit ihrem Smartphone Bewegungsprofile erzeugen. Sofern aus diesen Daten der Personenbezug entfernt wird, lassen sich damit ganz neue Erkenntnisse gewinnen. Es wird so früh wie möglich herausgefunden, welche Datenquellen dafür relevant sind und an welcher Stelle der unnütze Daten-Overload gefiltert werden kann. Auch externe Daten werden in die Konzeption einbezogen. Der Mehrwert für einen Anwendungsfall kann z. B. durch zugekaufte oder frei verfügbare Daten aus Datenmärkten stammen. Soziodemographische Daten oder Meinungsforschungsdaten aus Umfragen können so den entscheidenden Teil der Erkenntnisse liefern.
Ein Beispiel dafür ist das Targeting im Marketing. Ein Energie-Unternehmen möchte für Elektromobilität werben. Es hat bereits viele soziodemografische Informationen über Kunden in seinem Data Warehouse. Zusätzlich Informationen, welche Kampagnen auf bestimmen Kanälen zu welcher Kundentreue führen. Wenn weitere Werbekampagnen gestartet werden, kann die Performance der Kampagne präziser prognostiziert werden, wenn externe Informationen angereichert werden, in welchen Regionen die Kunden positiv zur E-Mobilität eingestellt sind und eine Garage am Haus zum Laden der Fahrzeuge haben. Letzteres kann mittels Satellitenbilder automatisiert erkannt werden, während die Meinung zu Themen von Meinungsforschungsunternehmen stammt. Damit lässt sich das Targeting für eine Kampagne passend zum Kunden durchführen und wird erfolgreicher.
Die gesammelten Use-Cases werden anhand verschiedener Kriterien priorisiert. Dabei ist zu beachten, wie wirtschaftlich erfolgsversprechend die Use-Cases sind, aber auch, welche Komplexität die Use-Cases beinhalten, wie aufwändig die Datenbeschaffung ist, wie hoch der praktische Nutzen für die Anwender ist und welches Potenzial die anfallenden Daten für künftige Analysen bieten.
Wenn ein Use-Case ausgewählt wurde, soll so schnell wie möglich ein testbarer, funktionierender Prototyp entwickelt werden. Diese Phase übernehmen die Data Scientists. Mit einem minimalen Aufwand wird versucht, einen Prototyp zu implementieren. Dabei funktioniert noch nicht alles vollautomatisiert und besitzt nicht die ideale Architektur, kann aber dazu verwendet werden, die Hypothesen zu validieren und das Nutzererlebnis mit den Daten durchzuspielen. Die Data Scientists wählen dafür geeignete Methoden und Technologien aus, um das gewünschte Ergebnis umzusetzen.
Wenn der Prototyp die gewünschten Ergebnisse liefert, kann dieser zu einer nachhaltigen Lösung implementiert werden. Erfolgreiche Use-Case-Umsetzungen demonstrieren die Bedeutung von Daten im Unternehmen und fördern das Umdenken. Je mehr Use-Cases auf diese Weise umgesetzt werden, desto mehr fließen die Möglichkeiten, die die Daten dem Unternehmen bieten, in zukünftige Lösungsfindungen ein. Es wird mehr mit Daten gedacht.
Falls der Prototyp nicht die gewünschten Ergebnisse liefert, kann iteriert werden. Dann wird analysiert, warum es nicht zu den erwarteten Erkenntnissen kam und was getan werden muss, um diese zu erhalten.

