Blogbeitrag von

Maxim Perl
Management Consultant

Als Machine Learning (ML) versteht sich ein Teilaspekt der künstlichen Intelligenz. Es handelt sich um ein Optimierungsverfahren, in dem Computer, basierend auf historischen Daten, selbstständig lernen, Aufgaben zu bewältigen. Im Fokus steht das Training von Algorithmen, um so Muster und Zusammenhänge in Datensätzen aufzudecken. Auf Basis dieser Analyse werden bestmögliche Entscheidungen und Prognosen getroffen.
In diesem Artikel geben wir Ihnen einen ersten Einblick in die Welt des Machine Learnings. Wir werden dessen Funktionsweise erläutern sowie verschiedene Lernalgorithmen und Modelle untersuchen. Zusätzlich beleuchten wir auch den Zusammenhang zwischen maschinellem Lernen, Deep Learning (DL) sowie künstlicher Intelligenz (KI) und stellen Ihnen einige Machine Learning Anwendungsbereiche vor.
Maschinelles Lernen umfasst ein großes Repertoire an Lernmodellen, die auf unterschiedliche algorithmische Techniken wie lineare Regression, Support Vector Machine (SVM), Entscheidungsbaum u.v.m. zurückgreifen. Bei komplexen und unvorhersehbaren Datensätzen besteht die Möglichkeit, einzelne Algorithmen einzusetzen oder mehrere zu kombinieren.
Je nach Datenart und angestrebtem Resultat stehen dabei vier Lernmodelle zur Verfügung. Innerhalb dieser kommen außerdem unterschiedliche algorithmische Verfahren zum Einsatz. Die Machine Learning Algorithmen dienen zur:
In diesem Lernmodell lernt die Maschine auf Grundlage von Beispielen. Es setzt sich aus Eingabe- und Ausgabedatenpaaren zusammen, wobei die Ausgabe als gewünschter Wert definiert wird.
Nehmen Sie an, das Ziel von Supervised Learning (SL) ist es, den Unterschied zwischen einem Hund und einer Katze zu erkennen. Die Trainingsdaten (Eingabe) umfassen Bilder von Hunden und Katzen. Es soll erkannt werden, wann es sich um eine Katze handelt. Hierfür werden alle Bilder von Katzen entsprechend als Output-Daten festgelegt. Der zugrundeliegende Machine Learning Algorithmus analysiert die im Laufe der Zeit gesammelten Trainingsdaten und beginnt, Übereinstimmungen, Unterschiede und andere logische Punkte zu identifizieren (Merkmale wie Ohren oder Schnauze). Dieser Prozess führt sich so lange fort, bis das System eine eigenständige Antwort auf die gestellte Frage generieren kann.
Gängige Anwendungsgebiete des überwachten Lernens:
Bei Unsupervised Learning stehen keine Ausgabedatenpaaren zur Verfügung, heißt die Trainingsdaten (Bilder von Hunden und Katzen) beinhalten keine richtigen Antworten. Stattdessen durchforstet dieses Lernmodell die bereitgestellten Daten und versucht, Muster und Zusammenhänge zu erkennen. Es greift dazu auf sämtliche relevante, verfügbare Informationen zurück.
Gängige Anwendungsgebiete des unüberwachten Lernens:
Semi-Supervised Learning (SSL) stellt eine Mischung aus den bereits genannten Lernmodellen im Bereich Machine Learning dar. Es greift sowohl auf spezifische Beispieldaten mit Zielvariablen als auch auf unbekannte Daten zurück. Im Vergleich zu anderen Lernmodellen analysiert SSL eine kleine Datenmenge mit einer bekannten Zielvariablen und eine große Datenmenge ohne Zielvariable. So kann der Lernprozess bereits mit einer geringen Menge an Daten beginnen.
Gängige Anwendungsgebiete des teilüberwachten Lernens:
Im Vergleich zum SL greift das Reinforcement Learning-Modell nicht auf direkte Trainingsdaten zurück. Stattdessen operiert es auf der Basis von zugelassenen Handlungen, Regeln und möglichen Endzuständen. Wenn das Ziel des Algorithmus fest oder binär ist, lernen Maschinen durch Mustererkennung.
Ist die vorgegebene Zielsetzung jedoch veränderbar, lernt das System durch Bestrafungen und Belohnungen. Diese Belohnungen sind numerischer Natur und als etwas in den Algorithmus eingebettet, was das System „erlangen“ will.
Gängige Anwendungsgebiete des verstärkenden Lernens:
Leider werden die drei Begriffe Machine Learning, Deep Learning und künstliche Intelligenz fälschlicherweise oft als Synonym zueinander verwendet. Maschinelles Lernen und Deep Learning (DL) sowie die dazugehörigen neuronalen Netze sind jedoch aufeinander aufbauende Teilbereiche der künstlichen Intelligenz (KI).
In der Hierarchie dargestellt sieht es folgendermaßen aus:
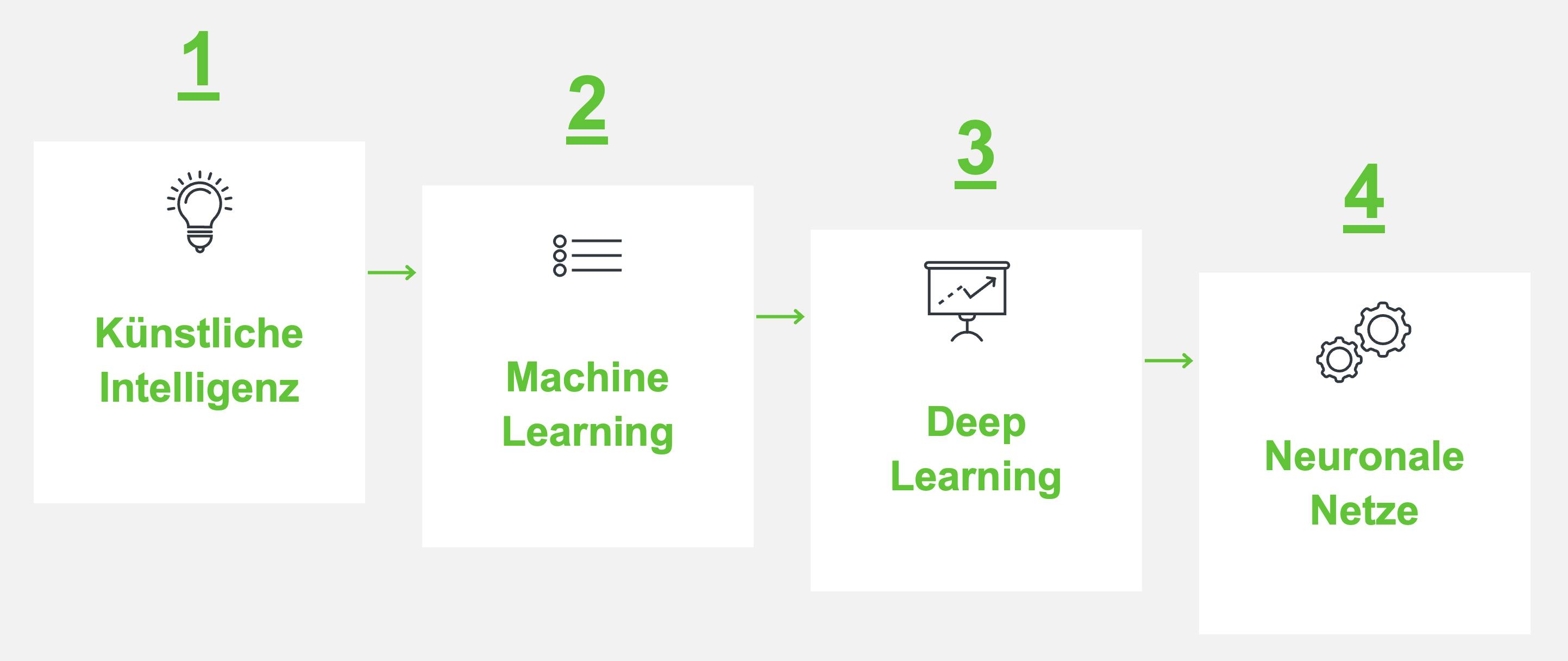
Deep Learning (DL) ist eine Kategorie des maschinellen Lernens, welche eine enorme Datenmenge durch eine Vielzahl von Schichten in neuronalen Netzwerken verarbeitet. Diese Systeme arbeiten auf einer komplexen Ebene, bei der sie mehrstufige Dateninterpretationen durchführen.
Beispiel: Nehmen wir ein Deep Learning System, das darauf programmiert ist, Häuser mit rotem Dach in natürlichen Bildern zu identifizieren. Es würde zunächst eine häusliche Form erkennen, dann seine Aufmerksamkeit auf Häuser lenken, innerhalb dieser Kategorie Dächer identifizieren und anschließend das spezifische Haus mit rotem Dach finden.
Gibt es einen Unterschied zum Machine Learning? Ja. Deep Learning ist eine Unterkategorie von ML, die mit deutlich komplexeren Algorithmen arbeitet. Deep Learning verwendet neuronale Netzwerke, um unstrukturierte Daten zu analysieren und in numerische Werte umzuwandeln. Machine Learning mathematische Prinzipien und statische Verfahren zurate, um durch Algorithmen aus Datenmengen Kenntnisse zu erwerben.
Künstliche neuronale Netzwerke bilden Neuronen des menschlichen Gehirns nach, sind also von der Idee daran angelehnt. Diese Nachbildungen, auch als Knoten bekannt, sind in verschiedenen, gleichzeitig funktionierenden Ebenen angeordnet. Sobald ein solcher Knoten ein numerisches Signal empfängt, wird es verarbeitet und an die anderen miteinander verbundenen Knoten weitergeleitet. Ähnlich wie in unserem Gehirn verbessert die neuronale Verstärkung die Fähigkeit zur Erkennung von Mustern, das Fachwissen und das allgemeine Lernen.
In der realen Umgebung erhalten wir Informationen, die eine Vielzahl von sensorischen Quellen wie Text, Bild, Audio und Video miteinander vereinen. Um alle Modalitäten voll umfassend zu nutzen, stand mit der Entwicklung des multimodalen Lernens der nächste Entwicklungsschritt an.
Multimodale Modelle sind sehr komplex sowie kosten- und zeitintensiv. Auch die Einordnung und Definition sind schwierig, da es keine einheitliche Definition gibt. Doch wie werden die einzelnen Quellen verarbeitet? Schauen wir uns dazu die am häufigsten verwendete Modalität, den Text, an.
Textdaten sind eine Goldgrube an nuancierten und geordneten Informationen. Diese Informationen werden mittels des Natural Language Processing (NLP) extrahiert. Die Quellen dieser Daten sind vielfältig und umfassen beispielsweise Social-Media-Posts oder andere Textarten.
Selbstverständlich besteht für Unternehmen die Möglichkeit, Machine Learning selbstständig im Unternehmen zu integrieren. Das gilt insbesondere, wenn es sich um klar definierte Aufgaben handelt oder bereits ausreichend Expertise vorhanden ist. Für diejenigen Unternehmen, die neu in der Welt des Machine Learnings sind, ist die Zuhilfenahme eines externen Beraters vorteilhaft.
Unsere Expert*innen von Cassini helfen Ihnen dabei, mögliche Engstellen in KI-Projekten frühzeitig zu erkennen und umsetzbare Projekte zu identifizieren. Ob bei der Digitalen Transformation, bei IT Services oder bei der Einführung einer geeigneten Unternehmenskultur – wir von Cassini unterstützen Sie dabei. Zu den Engstellen zählen oft Aspekte wie Rechenkapazität, Verfügbarkeit von qualitativ hochwertigen Daten und die Auswahl geeigneter Software. Auch die internen Voraussetzungen dürfen dabei nicht vergessen werden. Diese umfassen eine enge Zusammenarbeit zwischen den Abteilungen und eine Kultur der Innovation.
