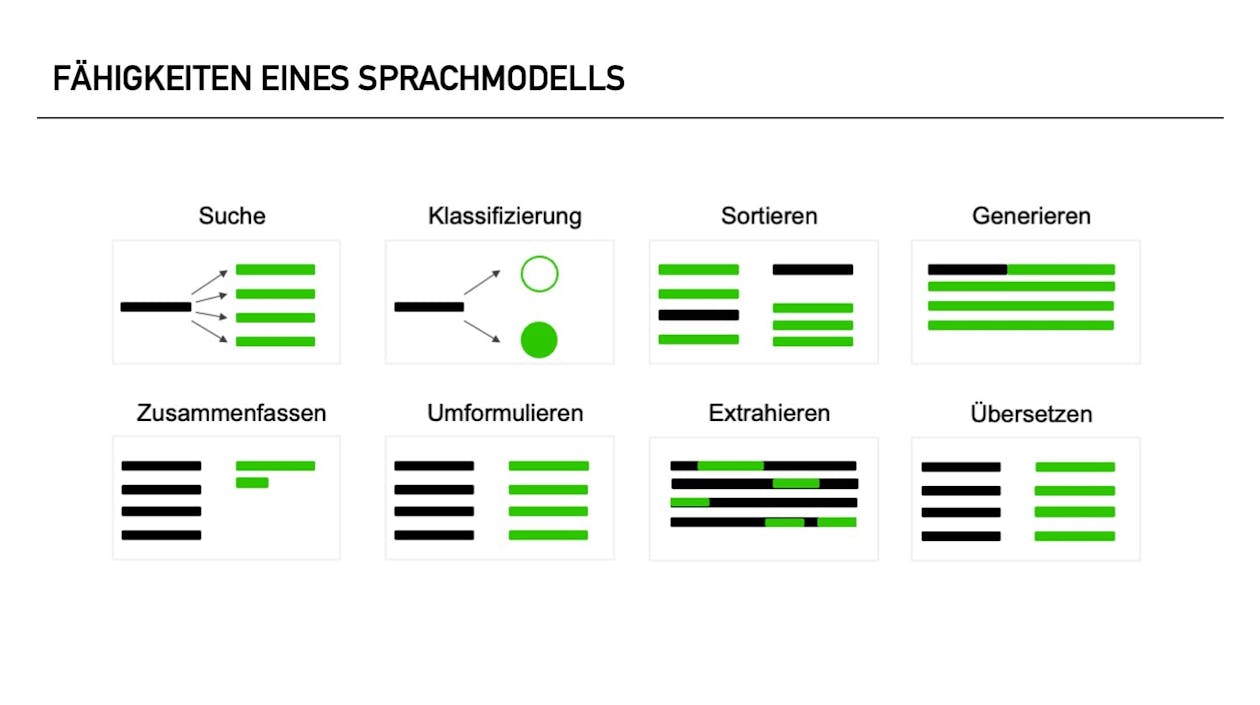
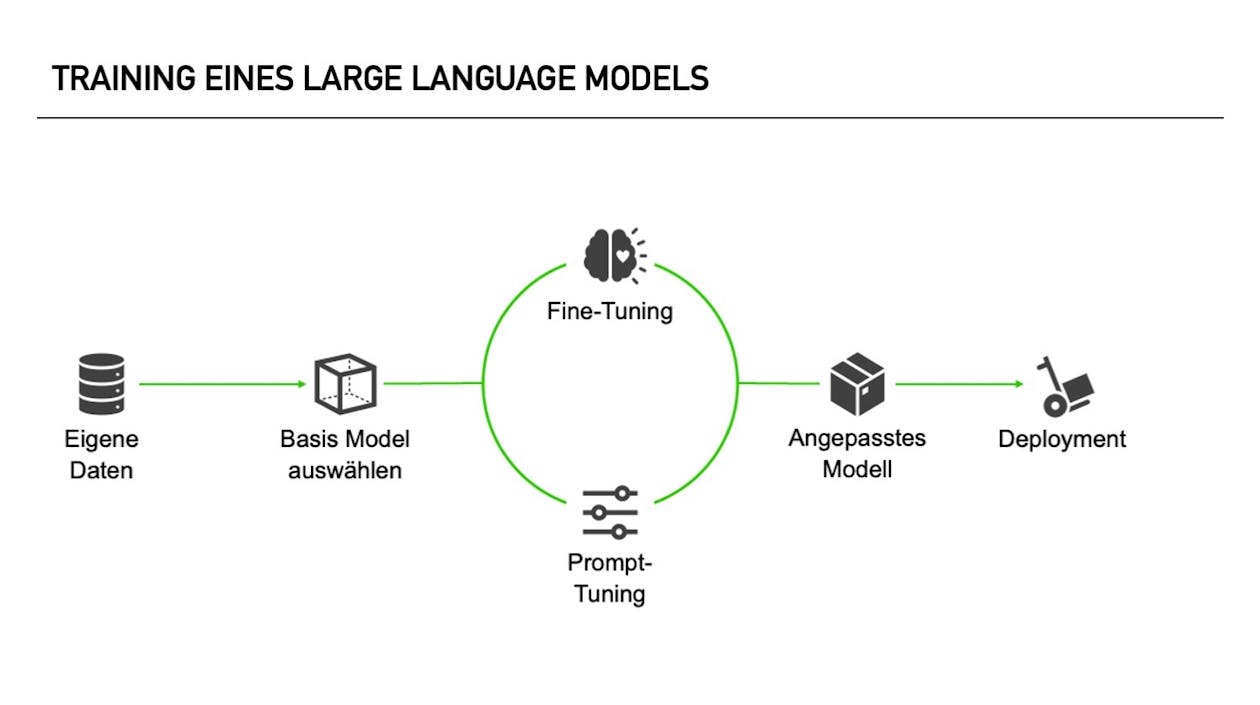
- Vorbereitung der Daten: Um ein LLM auf eigene Daten zu trainieren, müssen Sie zunächst über einen ausreichend großen und qualitativ hochwertigen Datensatz verfügen, der Ihre spezifische Aufgabe oder Domäne abdeckt. Dieser Datensatz kann aus verschiedenen Textquellen wie Büchern, Webseiten, Fachpublikationen oder internen Dokumenten stammen. Die Daten müssen in einem maschinenlesbaren Format vorliegen und aufbereitet werden, um das Training effizient zu gestalten.
- Auswahl des LLM-Modells: Es gibt verschiedene vortrainierte LLM-Modelle zur Auswahl, die als Ausgangspunkt für das Training mit eigenen Daten dienen. Diese Modelle sind bereits mit großen, allgemeinen Textdaten vortrainiert und verfügen über ein grundlegendes Sprachverständnis. Beliebte LLM-Modelle sind beispielsweise GPT-3, BERT oder Transformer.
- Fine-Tuning: Das eigentliche Training auf den eigenen Daten erfolgt durch den Prozess des Fine-Tunings (Feinabstimmung). Hierbei werden die Gewichte und Parameter des vortrainierten Modells an die spezifischen Eigenschaften und Anforderungen Ihrer Daten angepasst. Durch das Feintuning auf eigenen Daten erlernt das Modell die Sprachmuster und spezifischen Zusammenhänge Ihrer Domäne.
- Trainingsprozess: Das Training eines LLMs erfordert eine leistungsstarke Hardware, wie z.B. Graphics Processor Units (GPUs) oder Tensor Processing Units (TPUs), um die erforderliche Rechenleistung zu bieten. Der Trainingsprozess besteht aus mehreren Durchläufen (Epochen), bei denen das Modell die Trainingsdaten wiederholt durchläuft, um seine Parameter anzupassen und die Leistung zu verbessern. Je nach Umfang des Datensatzes und der Komplexität der Aufgabe kann das Training mehrere Stunden oder sogar Tage dauern.
- Evaluation und Feinabstimmung: Nach dem Training müssen Sie das Modell evaluieren, um die Qualität der Ergebnisse zu bewerten. Dazu können Sie Testdaten verwenden, die nicht im Trainingsdatensatz enthalten waren. Basierend auf der Evaluierung können Sie das Modell weiter optimieren und feinabstimmen, um bessere Ergebnisse zu erzielen. Dieser iterative Prozess kann mehrere Durchgänge erfordern, um die gewünschte Leistung zu erreichen.
Es ist wichtig zu beachten, dass das Training eines LLMs auf eigenen Daten Ressourcen, Fachwissen und Zeit erfordert. Der Prozess beansprucht in der Regel ein Team von Data Scientists oder maschinellen Lernexperten, um die beste Vorgehensweise zu bestimmen und das Training effektiv durchzuführen.
Abschließend kann gesagt werden, dass das Training eines LLMs auf eigenen Daten eine Möglichkeit ist, maßgeschneiderte und auf spezifische Anforderungen zugeschnittene Sprachmodelle zu erstellen. Es erfordert jedoch eine sorgfältige Planung, Vorbereitung der Daten und entsprechende Ressourcen, um erfolgreich zu sein.